在高端PC装机领域,内存早已超越了单纯的功能性硬件范畴,进化为兼具强悍性能与视觉表达的关键要元素。
统治者泰坦是海盗船内存产品线旗舰级型号,主打质感与美学设计,采用简约利落的金属磨砂外壳,灯光内敛,精准戳中了追求低调奢华的玩家群体,自发布至今,其颜值、性能、散热及稳定性表现都是有口皆碑,备受玩家青睐。
此前,统治者泰坦内存仅有经典的深灰色可选,虽然质感满满,但配色还是有点单调;近期,海盗船推出了全新的白色版本统治者泰坦,造型优雅、规格齐全,简直就是白色主题装机的绝配。
本文,要和大家分享的就是深灰色和白色两套配色的统治者泰坦,容量96GB(48GBx2),频率6000MHz C30,支持AMD EXPO和intel XMP一键超频技术。

统治者泰坦采用了高品质锻造铝制散热片,深灰色硬朗、白色优雅,表面阳极氧化处理,不仅能提供出色的散热性能,更赋予了它沉甸甸的质感和高级感。相比统治者铂金,泰坦的设计语言更为内敛和精致。


内存条顶部是贯穿式RGB导光条,内置11颗可独立寻址的RGB LED灯珠,光线均匀、饱和度高,配合侧面从两条镂空外溢的灯光,整体层次感极强。

在iCUE软件内,我们可以对每一颗LED的颜色和效果进行精细控制,实现从简单的静态色彩、呼吸、彩虹波浪到复杂的动态效果,比如随着系统温度变化、响应游戏内事件等效果。灯光效果也可以与机箱风扇、水冷散热器、键盘、鼠标等其他兼容iCUE的设备进行光效同步,营造更具沉浸式的灯光氛围。
统治者泰坦的导光条为可拆卸替换设计,用户可自行更换专属鳍片式散热模块(需单独购买),回归更纯粹的高性能内存条。这种模块化设计增加了统治者泰坦的可玩性,能够更好地融入不同风格的装机主题中。
不论无光环境还是RGB氛围,统治者泰坦都能轻松驾驭,上机效果非常棒。






黑白撞色搭配也别有一番风味,帅气十足。


除了高颜值特性,统治者泰坦的铝制金属散热马甲还具有良好的导热性能,能够有效地将内存颗粒工作时产生的热量散发出去,保证内存在长时间高负载运行时也能保持稳定,避免过热降频。在满载压力测试时,统治者泰坦的最高温度只有58℃左右,散热性能可见一斑。
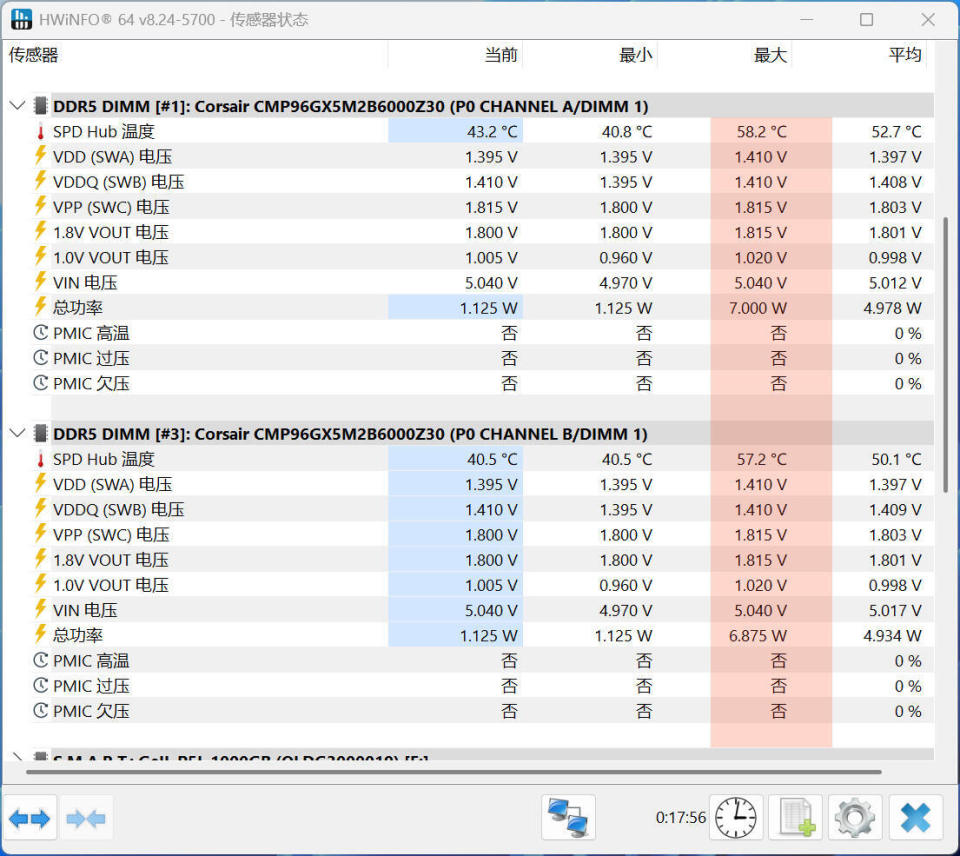
测试平台如下:
CPU:AMD 锐龙7 9800X3D
主板:华硕 TUF X870PLUS WIFI
显卡:微星 RTX5080 16G SUPRIM 超龙 SOC
内存:海盗船统治者泰坦96GB(48GB*2)6000MHz CL30
SSD:海盗船 MP600 Pro NH 8TB PCIe 4.0x4
水冷:海盗船 iCUE LINK 星光链 H150i LCD
电源:海盗船 RM1000X 1000W
机箱:海盗船 6500X 黑色

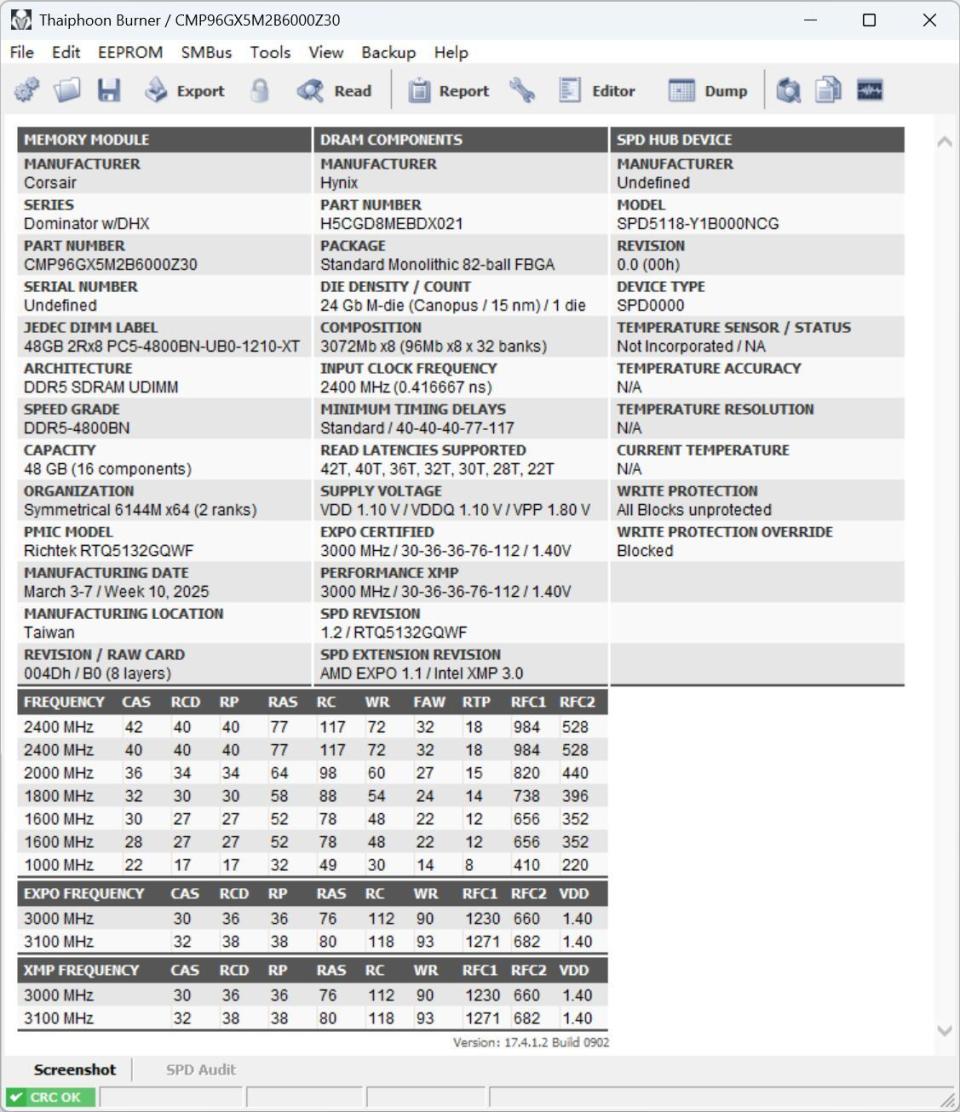
海盗船统治者泰坦采用SK海力士M-Die颗粒,默频4800MHz,时序40-40-40-77,支持intel XMP和AMD EXPO技术,可一键超频至6000/6200MHz(预设2个超频方案)。同时,配备定制高性能PCB板并板载电压电压调节功能,有助于保证信号的完整性和稳定性,减少高频信号传输中的干扰和衰减,这对DDR5高速内存来说至关重要。
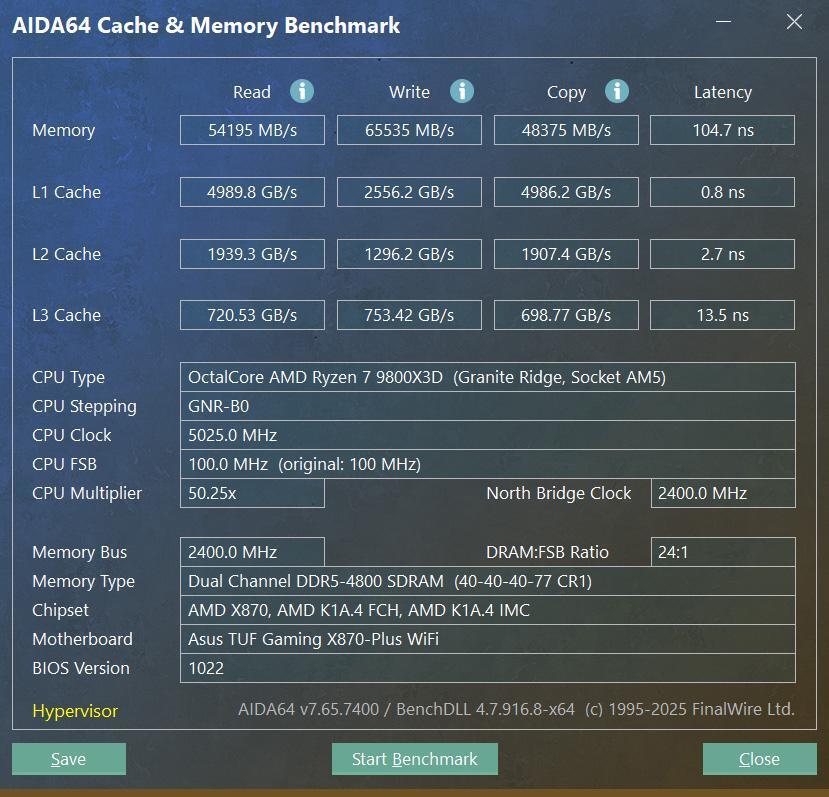
默认4800MHz频率下,内存读写速度54195 MB/s和65535 MB/s,拷贝速度48375 MB/s,延迟104.7ns。
开启EXPO一键超频至6000MHz,时序30-36-36-76,性能测试相比默认频率有大幅提升:
● 读取速度为62079 MB/s,比默认频率提升约14.5%
● 写入速度为86390 MB/s,比默认频率提升约31.8%
● 拷贝速度为58998 MB/s,比默认频率提升约22%
● 延迟为86.2 ns,比默认频率降低约17.7%
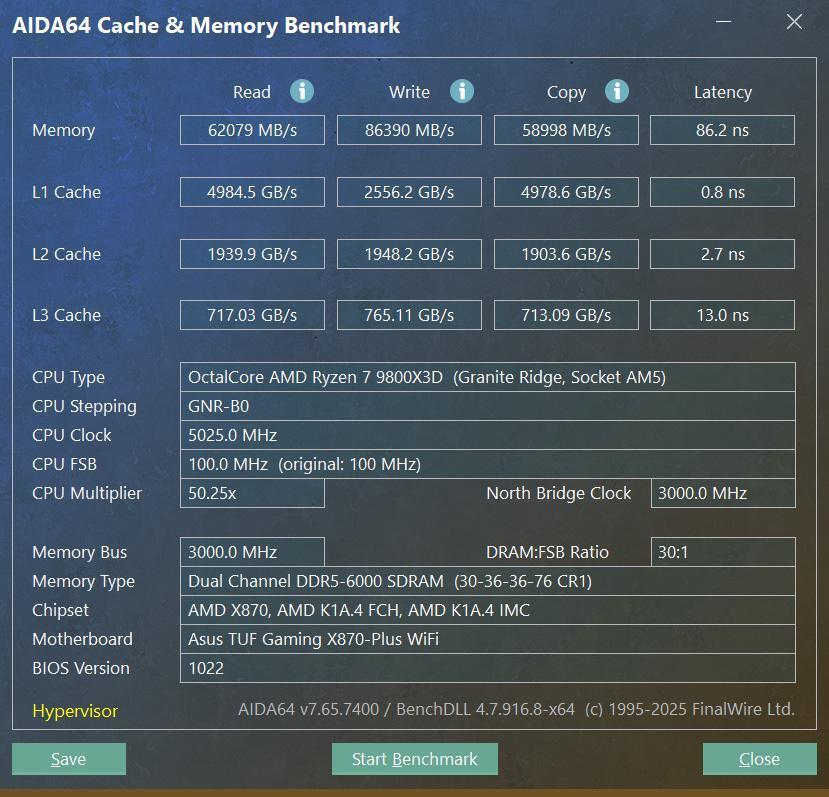
虽然A-Die颗粒的超频性能是公认的强,但像统治者泰坦这样单条48GB的大容量,还是得用M-Die颗粒,并且,随着技术的成熟,M-Die颗粒已经逐渐改善了“时序高”、“超频不稳定”等问题。
EXPO是AMD针对DDR5内存推出的一键超频技术,用户只需在AMD主板BIOS中启用预设的EXPO配置文件,即可自动应用6000MHz的配套参数,无需手动,大大降低了超频门槛,确保用户能够轻松获得内存更强性能。
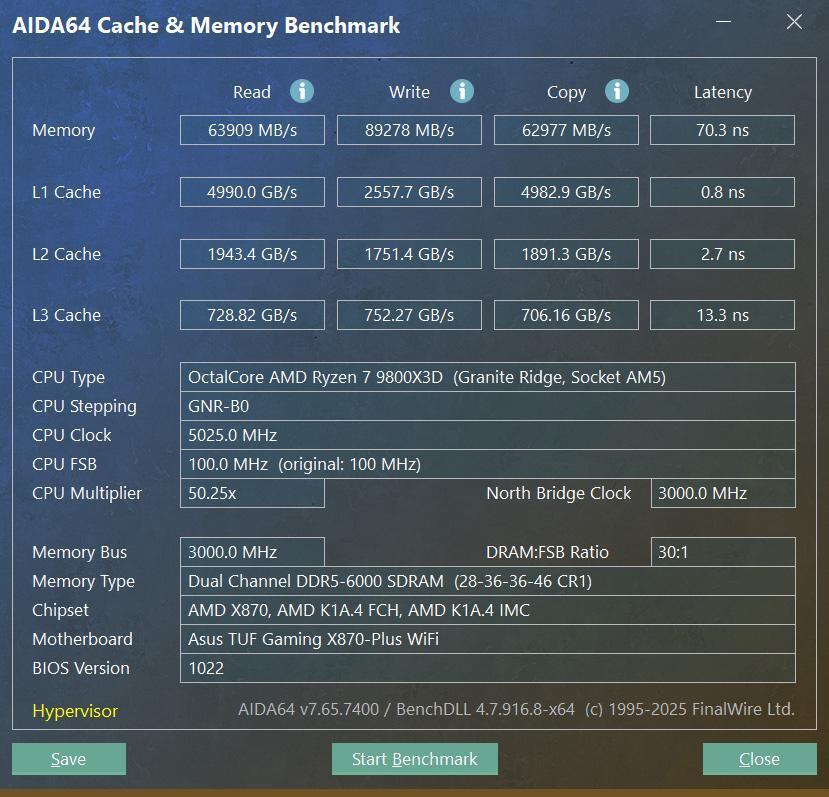
既然是预设,说明参数比较宽松,并不一定能发挥出内存的最佳性能。所以,我对统治者泰坦的EXPO 6000MHz的预设小参进行了二次精调,将时序进一步压低到CL28,各项性能又有了不小的提升,能0报错稳过TM5压力测试。
● 读取速度为63909 MB/s,比6000MHz CL30提升约2.9%
● 写入速度为89278 MB/s,比6000MHz CL30提升约3.3%
● 拷贝速度为62977 MB/s,比6000MHz CL30提升约6.7%
● 延迟为70.3 ns,比6000MHz CL30降低约18.4%
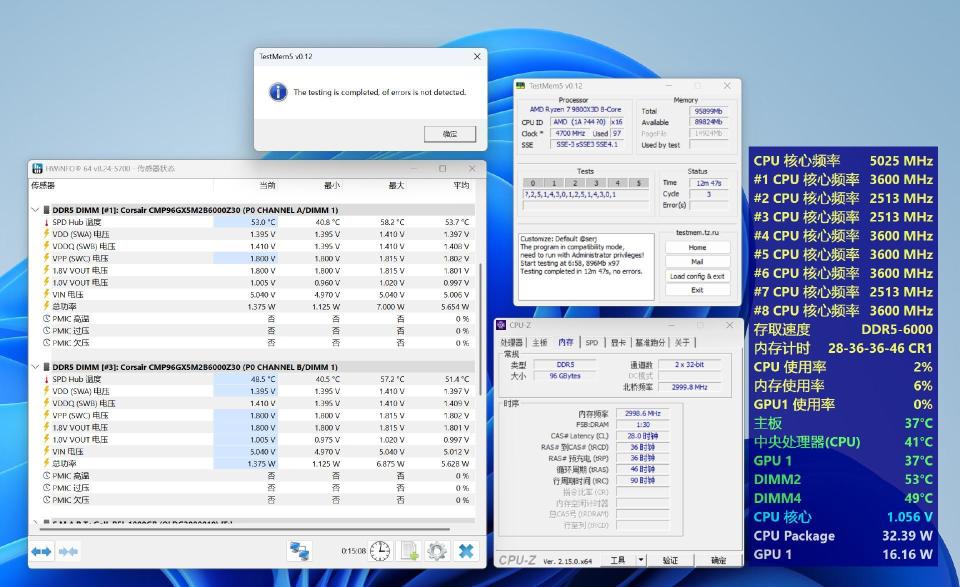
这套海盗船统治者泰坦的核心优势是容量大,其核心优势在于能够同时流畅运行更多程序和处理更大的文件,而不会感到明显的卡顿。
当内存容量充足时,我们可以同时打开多个浏览器标签页(比如几十个查资料的网页)、聊天软件、Office文档,甚至是一些专业软件(如 Photoshop、视频剪辑软)不会卡顿,程序之间的切换也会更顺畅。打开高分辨率的图片、编辑大型的Excel表格、处理复杂任务,或者加载大型游戏场景时,应用的加载速度更快,操作响应也更及时。
大容量内存不仅为同时运行多个应用程序提供了“缓冲”,也为单个高要求的应用程序内部的复杂运算和临时数据生成提供了必要的空间,进而减少数据交换的频率,加快运算速度。。例如,视频编辑软件 会将多个高分辨率视频流、复杂特效和预览帧加载到内存中。同样,3D渲染应用 也需要在活动内存中保存精细的几何数据、高分辨率纹理和光照信息。在这些情况下,内存容量不足不仅会拖慢多任务处理,更会从根本上削弱主要应用程序的高效运作能力,甚至可能导致任务(如渲染)失败。
即使我们没有刻意进行多任务处理,操作系统本身以及一些后台服务也会占用一定的内存。充足的内存可以确保系统有足够的“呼吸空间”,提高整体的响应速度和稳定性。随着操作系统功能日趋复杂,应用程序添加更多特性,以及文件大小(如视频分辨率)的持续增加,流畅运行所需的基准内存容量也在水涨船高。

随着AI模型的兴起,越来越多人热衷于在本地部署AI模型训练(尤其是大型语言模型、图像生成),在进行复杂数据分析时,大容量内存的重要性就会突显出来:支持加载更大更复杂的模型操作、处理更长的上下文/序列/更大的批次、减少磁盘I/O交换、提高多任务并发处理的效率等。
接下来,我使用UL Procyon商业套件对这台搭载海盗船统治者泰坦96GB大容量内存的主机进行了AI性能测试,感兴趣的小伙伴可以参考一下。
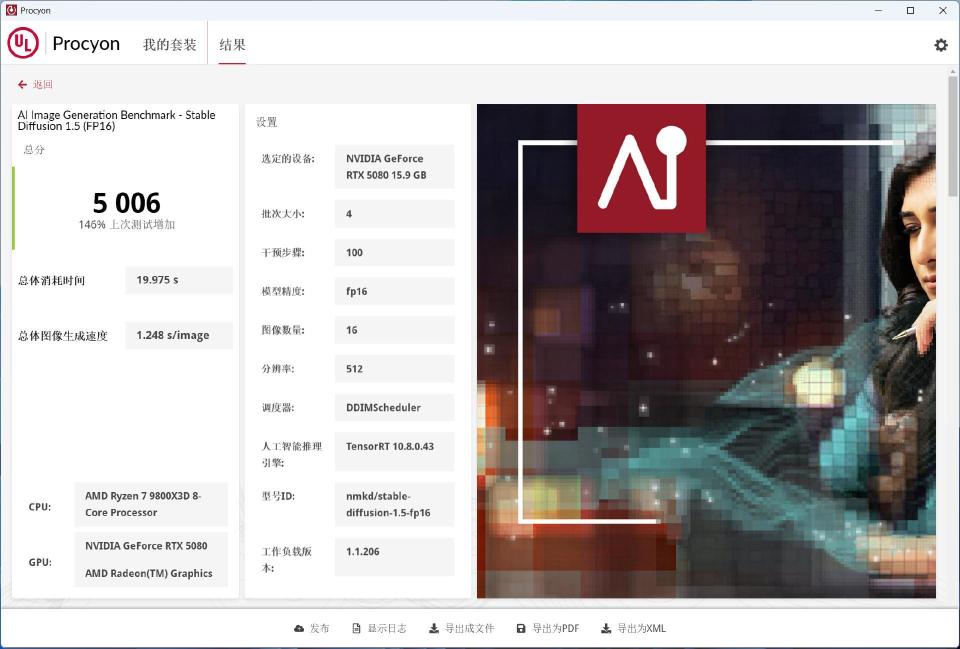
AI图像生成测试中,Stable Diffusion 1.5 FP16模型,测试总分5006,共耗时19.975s,速度1.248s/张。
批次大小:4
迭代步数:100
生成图像数量:16
图像分辨率:512*512
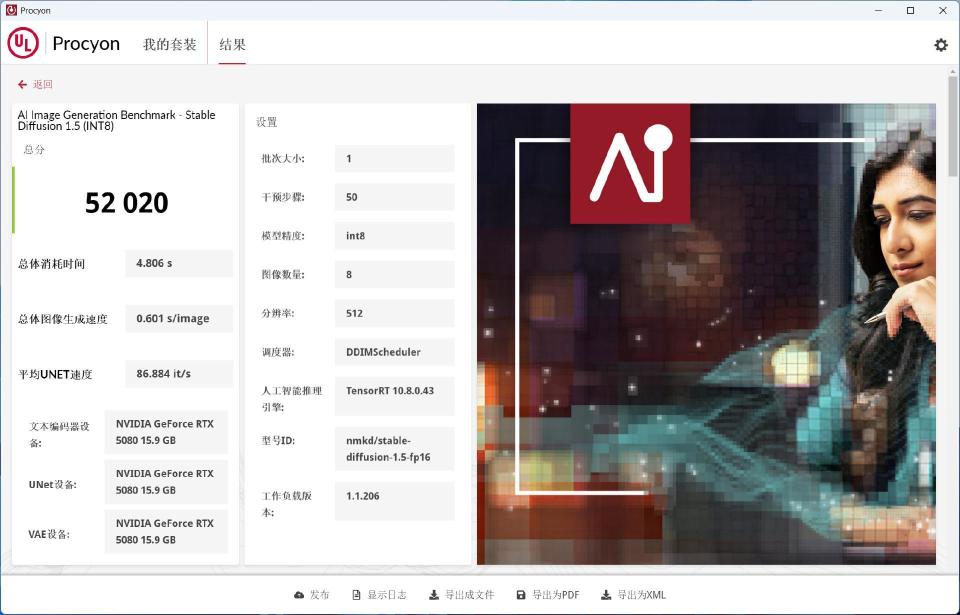
Stable Diffusion 1.5 INT8模型,测试总分52020,共耗时4.806s,速度0.601s/张,平均UNET速度:86.884it/s。
批次大小:1
迭代步数:50
生成图像数量:8
图像分辨率:512*512
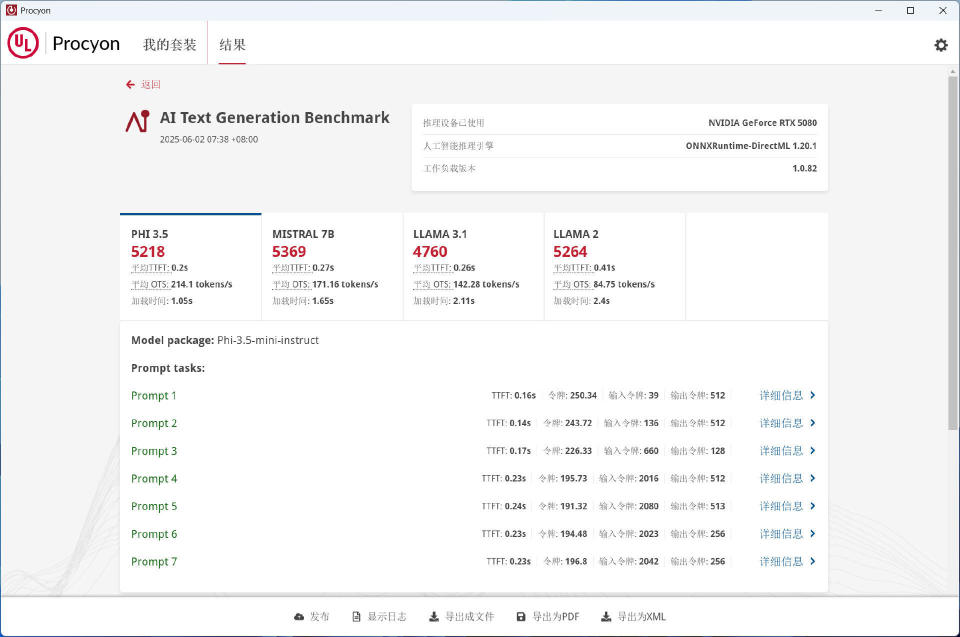
AI Text Generation Benchmark可以反复且一致地测试多个LLM AI模型,测试的模型包括PHI 3.5 mini、MISTRAL 7B、LLAMA3.1 8B 和 LLAMA2 13B,使用OpenVINO运行测试。
测试结果如下:
● PHI 3.5-mini:总分5218、平均TTFT 0.2s、平均OTS 214.1 tokens/s、加载时间1.05s;
● MISTRAL-7B:总分5369、平均TTFT 0.27s、平均OTS 171.16 tokens/s、加载时间1.65s;
● LLAMA3.1-8B:总分4760、平均TTFT 0.26s、平均OTS 142.28 tokens/s、加载时间2.11s;
● LLAMA2-13B:总分5264、平均TTFT 0.41s、平均OTS 84.75 tokens/s、加载时间2.4s。
OK,以上就是本次分享的全部内容,感谢大家观看。




